Overview and terms
Overlays are used to create alternative versions of activities. And they are used to store modifications made by a user as they go through an activity.
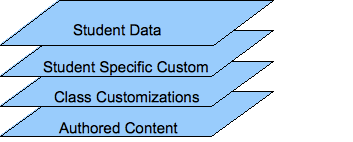
An Overlay contains a set of delta objects and a set of non-delta objects.
The delta objects add modifications to base objects. The non-delta objects are complete
objects which are contained by the overlay.
Within an overlay there can only be one delta object for any base object. Multiple overlays
can be layered to combine a multiple delta objects for one base object. The combination
of one or more delta objects with a base object is a composite object.
The views or controllers which are using OTrunk model objects work with composite objects. They do not need to know if the object is a composite object or a simple complete object.
Editing
When editing an overlay the same procedure is used wether you are a student going through an activity, or an author creating an alternative version of the activity. An author might have more affordances, so they could control which modifications go into the overlay and which modifications are to the original document. The code works by creating a CompositeDatabase for working on the overlay. When an object is requested from this CompositeDatabase a composite object is created that has a reference to the base object and the overlay object if it exists already.
To provide affordances for editing the overlay and the base object, a view can get an OTObjectService for both the CompositeDatabase and the base OTDatabase. The default object service for the view will be the object service which is managing the view's object. So to edit an overlay without having special views, the top level view just needs to be created with an object from an OTObjectService using the overlays CompositeDatabase and then everything will propagate down from that.
Notes
The current system uses overlays to manage user data ontop of author data. 3 OTDatabases are used to acomplish this.
- Author database
- Learner database
- Combination database
The combination database has the author database and differencing database. Whenever an object is requested from the combination database it returns a combination object which has a pointer to the authored object from the author database and a pointer to the learner object from the learner database. If there is no learner object yet then that will be null.
When a property is requested from the combination object, it first looks in the learner object, and then in the author object.
When a property is set on the combination object, it is always set in the learner object.
This approach is used a lot in virtual machine file systems now and is refered to as COW or Copy On Write.
There are a few interesting cases. If a new object is created by the learner a new combination object will be created to go on top of it. This is because this new object might have a reference to an existing authored object. And when that reference is requested from the new object a combination object needs to be returned so the COW can be maintained.
Doing it this way also leads to complications with the IDs of the object. When an object is requested with an author ID, the actual object returned will have a different ID. This has caused the most problems when doing lookup tables with object IDs. For example a technical hint uses a look up table to find the correct technical hint based on the current selected hardward device. The current selected hardward device is an OTObject. So the technical hint code, gets this object and asks for its ID and then trys to find the appropriate technical hint in its map. Doing this the obvious way fails because the ID returned by the current seleced hardware device is not its authored ID, but instead it is the ID of the combination object. The workaround for this particular case is to use a utility method in OTrunkUtil called getObjectFromMapWithIdKeys. What that method does is go through all the keys in the map, get their object and then see if it equals the object being looked up.
It seems it would be better to move this code out of the database level and into the OTObjectService. This should simply the database level some, and also possibly remove the need for the combination object altogether. At the OTObjectService dynamic OTObject instances are created and these instances could keep track of their authored and learner object. As well as many more overlay objects in between.
One difficultly with this approach is the object introspection and copying code. Currently this code works on the database level. This would mean that copying a learner object which is overlayed on a authored object would not do the right thing. The copy code gets the DataObject underneath the OTObject and copies that. So either the copy code needs to be revised to deal correctly with overlays, or it needs to work with the OTObjects instead of the OTDataObjects.
One question with the copy code is what should happen when an object that is actually stored as multiple layers is copied. Should all the layers be collapsed? Should each layer be copied? Copying each layer would require existing writable overlays the the layers could be stored in. That doesn't fit with the current model, so it seems they need to be collapsed.
Diagram
{kind=link}
{kind=link}
{kind=link}
{kind=link}